
Abstract
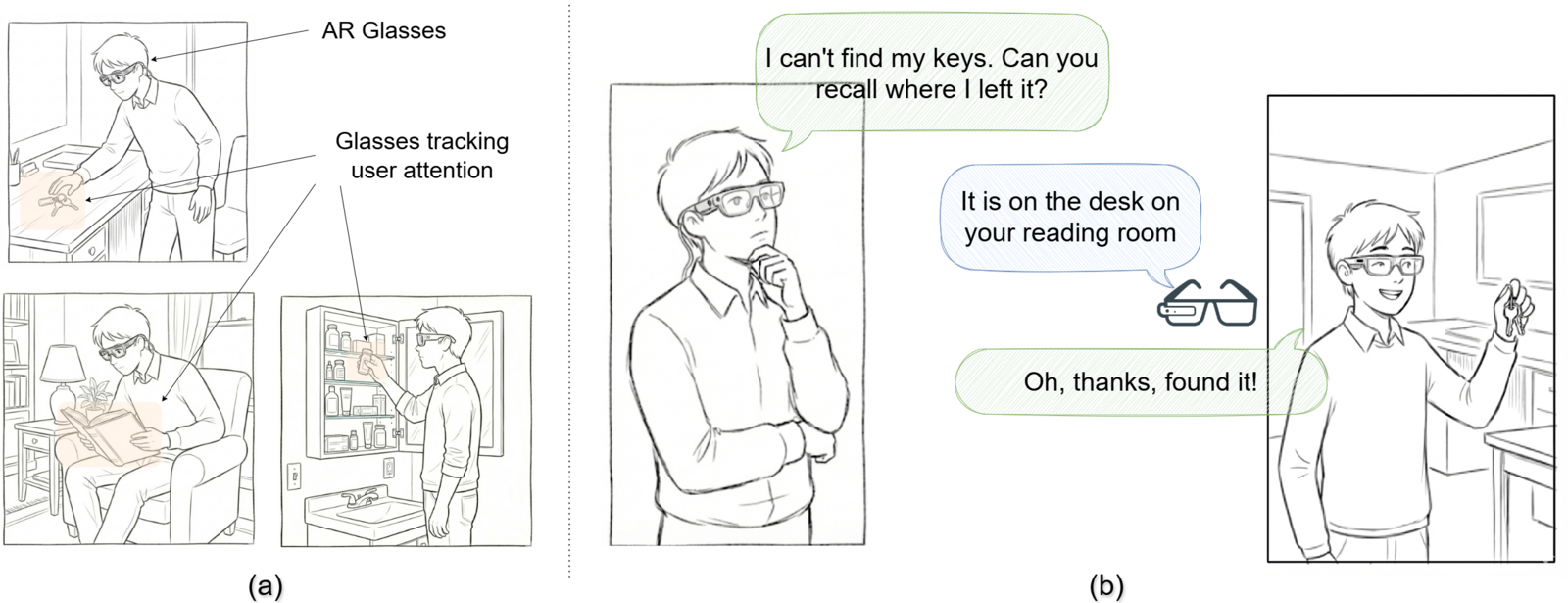
With augmented reality glasses, spatial computing can turn everyday experience into searchable memory. MemoLens focuses on super memory: accurately recalling the objects and people a wearer paid attention to or interacted with in the physical world.
We make this possible with two key ideas. First, we use eye gaze captured by AR glasses to identify attended visual regions and create compact memory snippets through gaze-aware spatio-temporal token compression. Second, we organize those snippets in a hierarchical memory structure so user prompts can retrieve relevant memories efficiently over long spans of experience.
We implemented MemoLens with Meta Aria AR glasses and evaluated it on more than 100 hours of egocentric video collected in real-world settings, where it supports accurate real-time retrieval under substantial compression.
System
MemoLens treats gaze as a proxy for attention. Incoming egocentric video is sampled, patchified, aligned with eye-gaze signals, and compressed into visual memory snippets that preserve the regions most likely to matter for later recall.
Gaze-Aware Input
We stream egocentric video and eye gaze from Meta Aria glasses to a paired smartphone for local preprocessing.
Compact Snippets
We merge redundant spatio-temporal visual tokens while retaining attended details.
Memory Tree
We organize short-term snippets into a hierarchy where upper levels summarize longer stretches of experience.
Top-Down Search
We first match user prompts to coarse context, then refine toward the clips needed for response generation.
Memory Creation
- 1Sample Frames. Short egocentric clips are sampled into frame-level visual inputs.
- 2Align Gaze. High-frequency gaze points are projected onto each frame.
- 3Score Patches. Gaussian heatmaps turn gaze into patch-level importance scores.
- 4Merge Tokens. Less important visual tokens are merged while attended details remain.
We sample frames from short egocentric clips and project high-frequency gaze points onto the image plane. A Gaussian heatmap spreads each gaze point into a dense importance signal, then patch-level scores guide which visual tokens should be preserved or merged.
This design preserves the parts of the scene that the wearer actually attended to, while reducing the storage and compute footprint required for always-on AR memory.
Results
Below, we summarize what we observe in the primary result figures.
Retrieval performance of MemoLens vs no-token merging
Top-3 retrieval accuracy and storage footprint under token reduction.


Overall performance of MemoLens






Citation
@inproceedings{alam2026memolens,
author = {Alam, Samiul and Siam, Shakhrul Iman and Zhang, Mi},
title = {{MemoLens}: Empowering Augmented Reality Glasses with Super Memory},
booktitle = {Proceedings of the ACM International Conference on Mobile Systems, Applications, and Services},
series = {MobiSys '26},
year = {2026},
note = {To appear}
}